







MLOps - решающее конкурентное преимущество?

Меня зовут Дмитрий Ходыкин, я AIML Project Manager в компании ITentika, и я попробую ответить на вопрос частным мнением автора материала, подкрепленным опытом "изнутри".
Введение
Все дело в том, что исторически люди вели бизнес интуитивно. Иными словами, процесс принятия решения сначала опирается на интуицию менеджера, а уже потом - подтверждается, или не подтверждается какими-то цифрами аналитики. К моменту получения достоверной аналитики внутри традиционного бизнеса могут пройти недели, месяцы, или даже годы на подбор аналитика, сбор данных, их очистку, сохранение, визуализацию. Зачастую, к этому времени менеджеры уже успевают наделать большое количество ошибок.
Современные технологии работы с данными, напротив, позволяют получать контринтуитивные предпосылки к принятию решений - инсайты. Такие инсайты нельзя получить каким-то логическим, интуитивным, или иным другим "человеческим" путем, так как они (инсайты) опираются на сложные зависимости внутри больших массивов данных, которые человеческий мозг не в состоянии вместить внутрь себя. И речь не идет об определении "больших данных". Даже в одной обычной таблице excel с миллионом строк и сотней столбцов содержится значительно больше информации, чем может переварить психика среднестатистического человека.
Гипотеза состоит в том, что определяющим фактором конкурентоспособности бизнеса может стать поставленный на системную основу процесс получения инсайтов из массива управленческих данных, позволяющих принимать контринтуитивные решения, вразрез интуитивным и плохо обоснованным решениям основных конкурентов. Далее рассмотрим предпосылки, которые могут лечь в основу подтверждения гипотезы.
Как сегодня обстоят дела в условном среднем бизнесе с управлением данными?
Для примера возьмем российский бизнес в "вакууме" среднего масштаба, который не занимается транзакциями (т.е. не имеет отношения к финтеху, клиентскому скорингу, e-commerce и т.п.). В таком бизнесе есть некая система, где хранятся данные управленческого учета, CRM - для управления коммуникациями с клиентами, бухгалтерская система, система внутреннего электронного документооборота. Если повезет, то есть и система ЭДО - юридически значимого документооборота с клиентами, и система кадрового учета. В каждой из перечисленных систем никакой "биг даты" - нет. Под "капотом" таких систем лежат традиционные реляционные базы данных с кучей небольших таблиц-справочников и таблиц-фактов.
Уже на примере среднего бизнеса мы имеем сразу несколько типов систем, которые, зачастую, никак не связаны между собой. Что в таком случае делать условному аналитику для, скажем, анализа объема документооборота, финансового анализа, или анализа взаимоотношений с клиентами? Да, верно, ему необходимо идти в каждую из систем, выгружать из них данные в excel, обрабатывать их, визуализировать, тут понятно...
Любой человек, в силу базовых законов, стремится сэкономить свою психическую энергию, поэтому от всего предельно сложного старается дистанцироваться. Если систем две и более, а данные в итоговом отчете нужны из каждой из них, то при объединении и обработке исходных таблиц появляются ошибки, упрощения, оценки, экспертное мнение и т.п.В итоге, уровень качества аналитики для принятия контринтуитивных решений - низкий или средний, если повезет персонально с отдельно взятым аналитиком, а также недостаточный (аналитик, все-таки, отражает в отчетах свое "человеческое" видение ситуации). Именно поэтому менеджеры в своей массе исторически не привыкли опираться на данные и мнение аналитиков для принятия важных и стратегических решений по принципу "своя рубашка ближе к телу", - свое мнение роднее и ближе.
Что нам готовит новый дивный мир?
Первые концепции научного подхода к работе с данными были сформированы во второй половине 60-х годов прошлого века, а само понятие науки о данных окончательно оформилось в нулевых годах 21-го века благодаря статье "Статистика" в Bell Labs Уильяма Кливленда.
Профиль William S. Cleveland в социальной сети LinkedIn
Наука о данных определила математический аппарат и набор подходов, которые позволяют:
-
Выделять из данных только те признаки (фичи, а по факту, - столбцы таблицы), которые каким-либо образом связаны с исследуемым явлением, процессом (их количественным измерением), что позволяет отсеивать цифровой шум и оптимально использовать вычислительные мощности для моделирования;
-
Определять, какие именно признаки (фичи) более всего влияют на изменение исследуемого явления, процесса (feature importance);
-
Применять "из коробки" довольно широкий спектр готовых моделей машинного обучения к данным для того, чтобы находить взаимосвязи признаков данных с исследуемыми явлениями, процессами. К таким моделям относятся: Random Forest, CatBoost, LightGBM и другие. При помощи моделей можно решать как задачи регрессии - насколько сильна связь признака и явления, так и классификации - относится ли признак к явлению (другие задачи в рамках статьи - затрагивать не будем);
-
Визуализировать и демонстрировать такие зависимости - для приятия привычных управленческих решений;
-
Переносить полученные зависимости на новые данные с целью предсказания поведения явления, процесса в будущем - для принятия хороших управленческих решений.
Наука о данных работает с огромными массивами данных, минимизирует человеческий фактор в обработке данных, а также имеет развитый инструментарий, в первую очередь, для исследовательской деятельности, например, Jupyter Lab, Google Colab, Apache Zeppelin, MS Data Studio и другие.
Это вполне закономерно, так как последние два десятилетия наука о данных развивалась в академической / научной среде, и лишь пять-шесть лет назад (с середины 2010-х) начала проникновение в бизнес-среду.
В связи с этим, совсем недавно, в 2018-м году появилась такая бизнес-область как MLOps, польза от которой заключается в "приземлении" академической науки о данных на бизнес-практики и требования.
Что такое MLOps?
MLOps - это набор решений и практик, которые позволяют внедрять модели машинного обучения в деловые практики, превращая их (модели) в инструмент поддержки принятия решений.
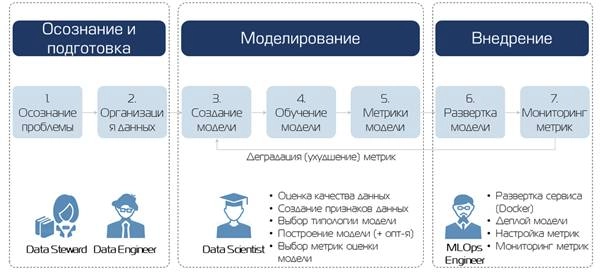
Цикл MLOps
1. Осознание проблемы
Если смотреть на жизнь модели машинного обучения широко, внутри бизнеса, то первым логическим шагом к ее построению является осознание проблемы, которую она (модель) должна решить. Уже на этом шаге можно столкнуться с некоторыми трудностями.
Во-первых, нужен человек, который бы мог выступить заказчиком построения модели - ML Product Manager (он же бизнес-аналитик в сфере машинного обучения). С точки зрения компетенций, человек должен обладать и широким бизнес-кругозором (может быть выходцем из других направлений, связанных с управлением данными либо процессами), и познаниями в области машинного обучения, в том числе необходим опыт практического построения моделей.
Во-вторых, ML Product Manager должен быть увлечен текущими задачами и проблемами бизнеса. С точки зрения рынка труда - это не простой "кадр" - дефицит специалистов составляет ~ 50% от потребности.

2. Организация данных
На данном этапе необходимо подготовить данные таким образом, чтобы подать их на "вход" модели машинного обучения. Как было описано выше, зачастую, данные разрознены и не связаны между собой. Кроме того, в них много "мусора" и пробелов. Модели этого не просто не любят, но и критически не приемлют.
На помощь в этом не легком деле приходят два специалиста:
-
Data Steward, который осуществляет надзор и управление данными внутри организации. Одна из ключевых обязанностей – поддержание в актуальном состоянии описательной части данных. Он лучше всех в организации осведомлен о наличии, доступности, структуре и применимости данных;
-
Data Engineer, который обеспечивает интеграцию источников исходных данных (тех самых реляционных баз данных с множеством табличек, которые еще называют OLTP) с хранилищем корпоративных данных (подробнее, см. концепцию DWH). Он настраивает алгоритмы обработки и обновления данных в DWH (ETL-процессы).
Результатом второго этапа является организация множества "красивых" таблиц внутри хранилища данных, каждый столбец которых представляет собой тот или иной признак (фичу) явления, или процесса, описанного в таблице. Кроме того, в таблицах отсутствуют "мусорные" и пустые значения.
Аналитическая (денормализованная) таблица
Можно переходить к следующему этапу - созданию модели.
3. Создание модели
Для изучения данных нужны математики. Те самые люди, которые освоили науку о данных и хорошо владеют:
-
Линейной алгеброй, поскольку каждый столбец из таблиц данных можно представлять в виде вектора в многомерном линейном пространстве (со всеми вытекающими из такого представления методами преобразования векторов);
-
Математическим анализом, поскольку признаки (фичи) из таблиц данных связаны (или не связаны) с числовым выражением исследуемого процесса, явления в некой функциональной зависимости, которую нужно исследовать (дифференциальное и интегральное исчисления);
-
Теорией вероятности, поскольку исследуемые явления и процессы описываются множеством цифр, имеющих определенное вероятностное распределение.
Математиков, которые способны строить модели машинного обучения, называют Data Scientist'ами. Кроме самой математики, они обязаны хорошо владеть навыками программирования. Основным языком программирования таких специалистов является Python.
Применяя свои навыки программирования и знание математики, Data Scientist описывает модель в упомянутых ранее инструментах, таких как Google Colab:
Пример построения базовой модели в интерфейсе Google Colab
Например, для решения задачи классификации может быть использована готовая (уже описанная) модель RandomForestClassifier, которая содержится в Python-библиотеке sklearn. Что бы применить эту модель, специалист предварительно импортирует ее в свой код.
4. Обучение модели
Под обучением модели понимается исследовательская работа по поиску зависимостей между признаками (фичами) данных и числовым выражением исследуемого явления, процесса.
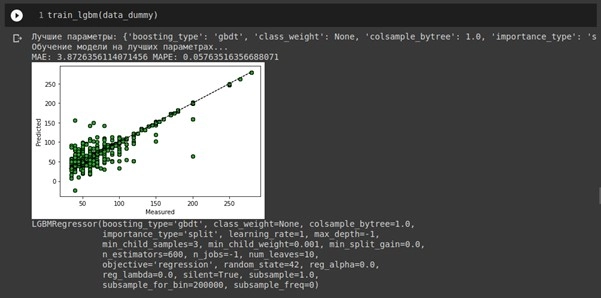
Пример обучения модели в интерфейсе Google Colab
Обучает модель Data Scientist на тех данных, которые ему предоставил Data Steward / Data Engineer. Тут стоит отметить, что речь идет именно о системном бизнес-подходе. В научно-исследовательских целях данные, зачастую, самостоятельно готовит и обрабатывает Data Scientist.
Учебные данные обычно делят на три части (датасета):
-
Тренировочный набор;
-
Тестовый набор;
-
Валидационный набор.
На первых двух наборах модель обучается и отслеживается качество этого обучения через специальные метрики (о метриках в п.5).
Валидационный набор данных модель не "видит" во время обучения. Его откладывают для последующей оценки готовности модели "переваривать" новые данные и делать на их основе прогноз.
Качество такого прогноза служит показателем эффективности как самой модели, так и работы Data Scientist'a. Чем точнее модель работает на предсказание, тем выше ее потенциальная польза для бизнеса (хотя это не всегда так, об этом стоит поговорить отдельно).
Результатом работы Data Scientist'a является один файл, в который он сохранил ("замариновал") модель со всеми найденными зависимостями в данных. Теперь эти зависимости можно выпускать как джина из бутылки и "натравливать" на новые данные, генерируемые бизнесом ежедневно. Теперь модель может их обобщить и сделать на основании обобщения некий сценарный прогноз. Однако выпустить модель пока некуда, нет среды для ее размещения (об этом в п. 6).
5. Метрики модели
Метрик для оценки качества моделей машинного обучения достаточно много. Наиболее интерпретируемыми для бизнеса будем считать MAPE - для задач регрессии и F1-Measure - для задач классификации.
MAPE (Mean absolute percentage error) - средняя абсолютная ошибка в процентах. Например, если стоит задача предсказания средней заработной платы в зависимости от должности, опыта и региона проживания работника, то MAPE покажет на сколько процентов предсказание модели будет в среднем отклоняться от среднего значения истиной выборки. Если среднее истинное значение 50 т.р., а модель предсказала 52 т.р, то MAPE = 4%. Чем ниже данный показатель - тем лучше.
F1-Measure (F-мера) несколько сложнее. Если в двух словах, то чем ближе она к единице (1), тем лучше, но что из себя представляет эта метрика по сути? Предположим, нам нужно предсказать марку автомобиля на фото. Если в обучающем наборе большинство автомобилей было марки А, то модель на учебных данных научится делать это легко, но когда вместо учебных данных в нее начнут подавать "живые" данные, то доля ошибки будет очень высокой. Поэтому необходимо оценивать не только способность модели находить автомобили марки А среди общей подборки фото автомобилей (точность), но и долю правильно классифицированных фото марки А среди общего количества фото марки А (полноту). Среднее гармоническое значение между точностью и полнотой - это и есть F-мера.

Теперь, когда сложилось некоторое понимание о метриках оценки качества модели, перейдем к их системному отслеживанию, но для начала, необходимо подготовить к этому саму модель.
6. Разворачивание модели
После того, как Data Scientist закончил свою работу и предоставил файл готовой модели машинного обучения, за работу принимается MLOps Engineer. Его основная задача - обеспечить разворачивание и эксплуатацию модели. Рассмотрим (не единственно) возможную архитектуру для бизнес-среды.
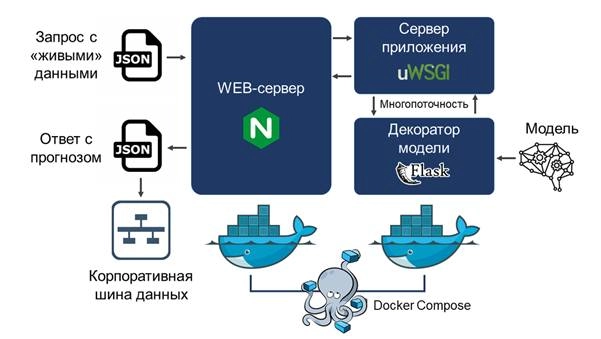
Архитектура разворачивания модели машинного обучения
Среда для разворачивания может быть подготовлена либо на внутреннем сервере бизнеса, либо на арендованном виртуальном сервере с установленной операционной системой класса GNU Linux, например, Ubuntu / Debian / Fedora и др. Под средой понимается необходимое программное обеспечение, указанное на рисунке.
Возможны варианты использования других сред (например, облачных), но об этом стоит писать отдельно.
Для того, чтобы модель могла принимать "живые" данные и пропускать их через свои внутренние зависимости, модели нужен декоратор. Он (декоратор) представляет из себя функцию, написанную на языке программирования Python и выполняющую несколько задач:
-
Распаковка и проверка на корректность подаваемых на вход модели данных, а также конвертирование данных в необходимый формат, если это требуется;
-
Вызов функции предсказания для подготовленной модели;
-
Возврат полученного предсказания в ответ на поступившие в модель данные.
Для декорирования моделей часто используется Python-фреймворк Flask, либо FastAPI. Эти фреймворки локаничны и функциональны одновременно, а также удобны в использовании.
Для того, что бы запрос с "живыми" данными пришел к модели, необходима точка входа для обработки запроса. Эту роль в нашей архитектуре играет web-сервер NGINX, который слушает указанные ему порты и ожидает запрос для последующей обработки.
Web-сервер связан с сервером приложений uWSGI через свой внутренний протокол. Формально, web-сервер записывает поступивший запрос в файл, а сервер приложений читает из него. Ответ на запрос от декоратора сервер приложений также записывает в файл, из которого читает уже web-сервер. Сервер приложений необходим для распараллеливания запросов. Если бы его не было, то в каждый момент времени к модели можно было бы обратиться лишь один раз, что никак не годится для сценария бизнес-использования модели.
Web-сервер, а также сервер приложения с декоратором "упаковываются" в так называемый контейнер, который позволяет изолировать друг от друга отдельные логические блоки получившегося приложения со всеми их зависимостями. Делается это для автоматизации и типизации разворачивания приложений на сервере.
К примеру, если всю модель с ее окружением придется перенести на другой сервер, то при помощи файлов настройки контейнеров это можно сделать при помощи нескольких команд, вместо длительной и трудоемкой настройки каждого отдельного компонента приложения.
Для контейнеризации в нашей архитектуре используется Docker, а функцию одновременного и параллельного управления всеми контейнерами выполняет Docker Compose. Именно выполнение команды для последнего инструмента позволяет "поднять" всю конструкцию после настройки и отладки.
Итак, наша модель готова к приему "живых" данных и возврату прогноза / предсказания для них. Полученный прогноз / предсказание мы можем использовать по месту его востребованности.
Например, прогноз ухода сотрудника можно использовать в кадровой системе, для чего он (прогноз) передается в нее через интеграционную шину данных (ПО для интеграции систем), либо через web-сервис по API.
7. Мониторинг метрик
Со временем, подаваемые на вход модели данные могут изменяться. Это означает, что первоначально найденные и "замаринованные" в модели зависимости перестают работать, либо работают хуже для прогнозов / предсказаний.
Для того, чтобы модель не подвела менеджеров при принятии решений, метрики качества модели необходимо отслеживать. Настройка и автоматизация отслеживания ухудшения (деградации) метрик качества модели машинного обучения - задача для MLOps Engineer'a.

Динамика метрик, рассмотренных в п.5 (или иных) визуализируется при помощи интерактивных отчетов (дашбордов) в специализированных системах. Например, можно использовать Kibana, Power BI и т.п.
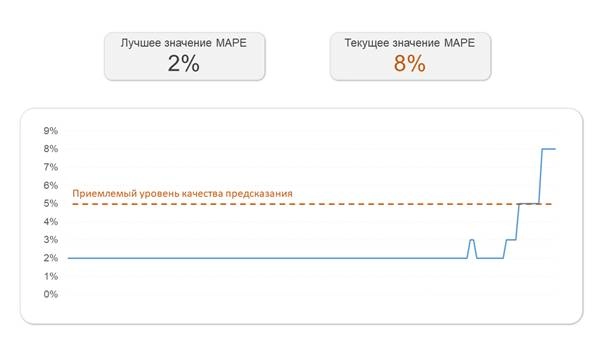
Дашборд для отслеживания деградации метрик качества модели
В том случае, если метрика выходит за границу приемлемого качества предсказания / прогноза, работу по изучению данных и повторному обучению модели проводит Data Scientist. Цикл MLOps повторяется.
Выводы
Описанная выше система управления использованием моделей машинного обучения в бизнес-практиках позволяет на регулярной основе с контролируемым уровнем качества получать не очевидные на первый взгляд подсказки (инсайты) для принятия решений.
Безусловно, наличие такой контринтуитивной информации может позволить менеджеру принять решение, которое не в состоянии принять менеджер конкурирующей компании, опирающийся исключительно на свою интуицию и традиционную "человеческую" аналитику.
В условиях предельно жесткой конкуренции на рынке за покупателя, а также в условиях, когда товары массового потребления у разных компаний мало чем отличаются друг от друга, именно контринтуитивные решения могут дать бизнесу решающее конкурентное преимущество.
Опубликовано 07.11.2022