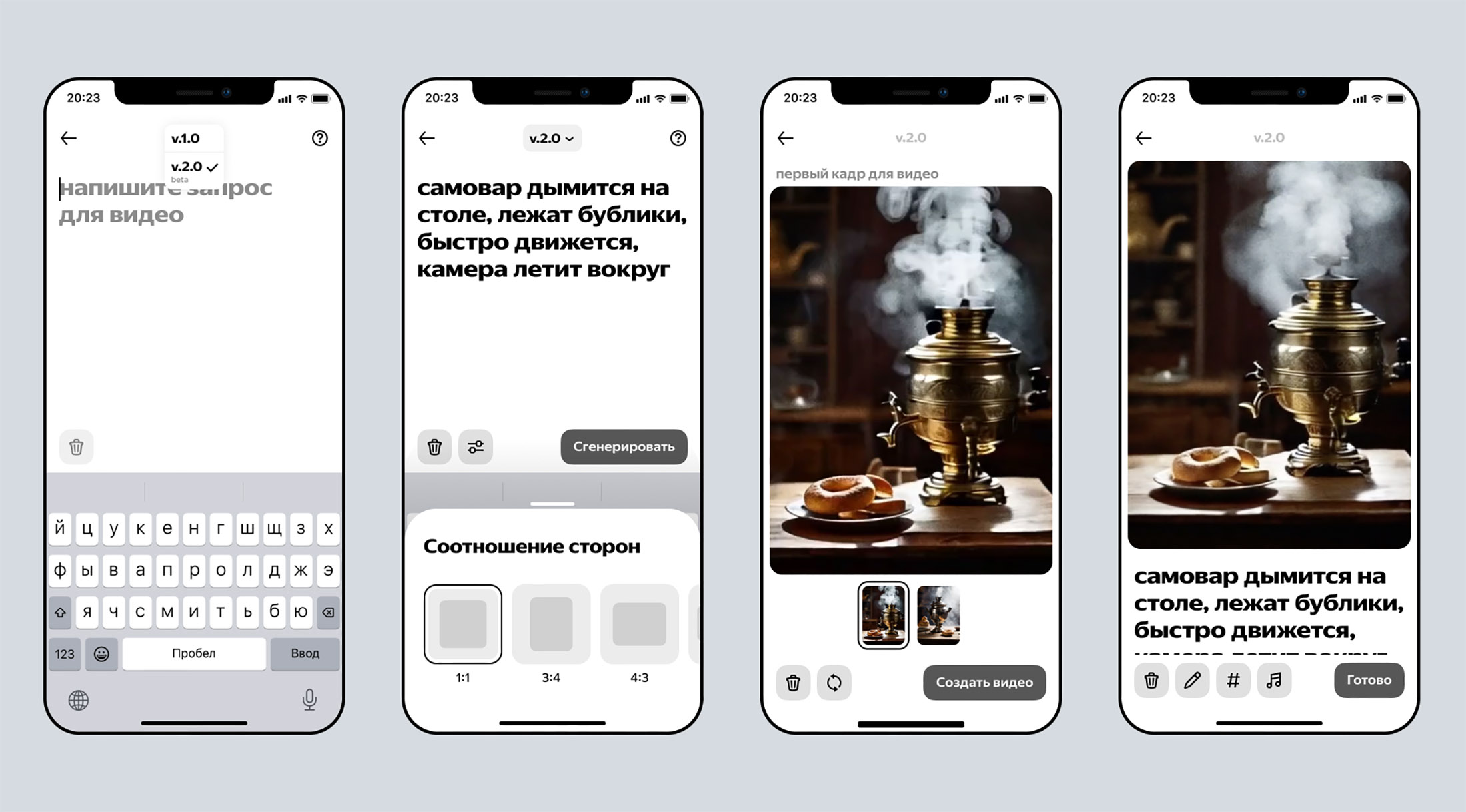
Представлена бета-версия нейросети YandexART (Vi) для создания пятисекундных видео
Компания представила предыдущую версию модели для генерации видео по текстовому описанию в августе прошлого года. Прошлое решение позволяло получать анимации, которые выглядели так, будто двигалась камера, но не объект. Кроме того, от кадра к кадру объекты при генерации значительно менялись. YandexART (Vi) научилась воссоздавать реалистичные движения, а также учитывать связь между кадрами — благодаря этому видео получаются более цельными и плавными. Чтобы нейросеть могла справляться с этой задачей, её обучили на роликах с движущимися объектами, например, с едущим автомобилем или крадущимся котом.
Нейросеть создаёт последовательность кадров, которые незаметно сменяют друг друга и образуют плавное видео. На вход модель получает текстовое описание от пользователя о том, что должно быть в кадре (например: «Носорог танцует хип-хоп в сумрачном лесу»), и создаёт картинку, с которой будет начинаться анимация. Затем модель постепенно превращает цифровой шум в последовательность кадров, опираясь на это изображение и текстовый запрос.
YandexART (Vi) доступна в приложении Шедеврум.