







Диалоговый робот с ChatGPT: можем ли мы контролировать его ответы?

Изображение создано нейросетью на shutterstock.com
Около 90% заказчиков, которые приходят в «Наносемантику» за автоматизацией коммуникации, хотят «подключить бота к ChatGPT». Под этой формулировкой скрывается запрос на использование больших языковых моделей (LLM) для обработки пользовательского обращения и генерации ответа диалогового робота.
Совсем не обязательно, чтобы используемая модель была именно ChatGPT, который сам по себе является чат-ботом с генеративной нейросетью. Клиенты открыты к рассмотрению предложений от других поставщиков LLM и проявляют интерес к созданию кастомизированных решений на базе их данных, но «чтобы модель отвечала как ChatGPT».
«Подключите нам ChatGPT»
Как вендор интеллектуальной корпоративной платформы для разработки ботов мы видим, что бизнес еще не до конца сформировал ясное понимание о роли больших языковых моделей в ключевые коммуникационные процессы. ChatGPT накопил в себе много фактической информации, может рассказать шутку, сделать перевод, сгенерировать поздравление и даже написать научную работу. Это впечатляет, но как это поможет бизнесу в автоматизации процессов коммуникации? Как создать не просто собеседника на отвлеченные темы, а помощника для заказчика?
Что означает запрос «говорить как ChatGPT»? Под этой формулировкой обычно скрывается желание настроить базу знаний бота на определенную деловую сферу. Заказчики хотят, чтобы бот общался с клиентами по продуктам и услугам конкретной компании, собирал и записывал обращения потребителей, вел работу с документами согласно регламентам компании, выполнял рутинные повторяющиеся действия, например, оформлял заявки или подключал новые услуг, транзакции, т.д. Но при этом заказчики ожидают, что бот будет общаться с клиентами на естественном языке как живой человек, а не отвечать набором заранее записанных фраз. То есть бот должен понимать разные варианты выражения одного и того же смысла, помнить историю диалога, реагировать на эмоциональный тон собеседника, узнавать клиента и помнить, в каком стиле предпочтительно вести с ним диалог. Такой бот должен также различать интонации речи, голоса взрослых и детей и учитывать эту информацию при стилизации своих ответов. У бота должна быть «коммуникационная личность» ‒ способность обучаться генерировать ответы в заданном стиле, соответствующем его визуальному образу и «истории».
Но есть и подводные камни
Крупные языковые модели открывают большие возможности для адаптивности и интерактива, но они же создают и потенциальные проблемы: например, так называемые «галлюцинации» (генерация некорректной или вымышленной информации) и сложности в управляемости ответов.
LLM по сути является «черным ящиком»: никто кроме самих разработчиков не может проанализировать реальные корпусы данных, использованные для обучения этих моделей. «Протоколы» обучения также закрыты для широкой аудитории. Все это создает гипотетические риски: в обучающий датасет преднамеренно могут быть внесены данные, которые при определенных условиях нарушат работу модели в важных бизнес-процессах. Такие ошибки могут быть восприняты как «галлюцинации» языковой модели, что представляет угрозу в критически важных сценариях.

Еще один важный аспект ‒ точность и надежность ответов, которые имеют критическое значение в корпоративной бизнес-среде. Неправильные или не соответствующие стандартам ответы могут повлиять на восприятие бренда и доверие клиентов. Поэтому с одной стороны, большие языковые модели имеют огромный потенциал для улучшения взаимодействия с клиентами, с другой ‒ использоваться их нужно с осторожностью и под контролем.
Что делать
Чтобы преодолеть подобные вызовы, на наш взгляд, нужна интеграция генеративного ИИ (GenAI) с существующими системами и базами данных компаний. Улучшить опыт также поможет разработка гибридных подходов, которые сочетают в себе сценарные и генеративные методы. В нашей практике мы используем два алгоритма работы с ChatGPT при разработке виртуального ассистента.
Во-первых, для управления ответами модели мы можем писать промпты, или инструкции: изначально давать ей указания «Говори так и этак, на такие вопросы отвечай, а на такие ‒ нет». Промпт передается функцией в начале диалога или с каждым запросом, это зависит от логики и целей диалога. С помощью нашей диалоговой платформы мы можем настроить своеобразный пайплайн: сначала ее средствами проверить, удалось ли классифицировать и понять запрос, и есть ли в базе знаний готовый ответ. Если есть, то выдается он, если нет, то тогда идет обращение к ChatGPT. Но риск, что ответы иногда все же будут нечеткими, остается, так как ChatGPT ‒ cложная генеративная нейросеть и действует по своим алгоритмам. Мы также можем дополнять ответ от GenAI припиской в самом ответе и предупреждать собеседника, что ответ сгенерирован нейросетью.
Во-вторых, мы можем обучать диалогового робота по предоставленным компанией материалам. При этом для LLM важно, чтобы загруженный материал был однородным, а не разномастным, и его не рекомендуется сильно перегружать данными. Иначе модель может выдать достаточно непредсказуемый результат. Часто требуется дополнительная работа с исходными данными и помощь специалистов по data science.
Оба подхода были использованы, например, при создании популярного цифрового политического алгоритма ИИ, и остаются актуальными в наших разработках сложных цифровых аватаров и роботизированных систем.
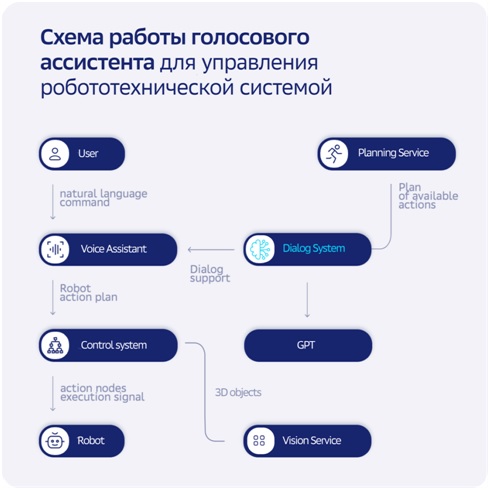
Схема работы голосового ассистента для управления робототехнической системой. «Мозговым центром» является диалоговая платформа.
Какую именно LLM использовать в боте
Те разработчики, которые уже опробовали популярный ChatGPT, упоминают также и затруднения, с которыми сталкиваются при внедрении. Проанализировав их опыт, можно выделить сложности с доступом к ChatGPT из России, проблемы при работе с длинными промптами, порой долгое ожидание ответа, и особенно «корявый» русский язык в ответах ‒ неточность формулировок, неестественные обороты речи, ошибки и нарушения привычной структуры предложений. В этом случае перспективным выглядит будущее LLM российских вендоров: Яндекс и Сбер активно разрабатывают свои большие модели.
Но и здесь есть подводные камни. Данные решения облачные, а значит, потенциально могут появиться проблемы при работе с персональными данными: гарантии их конфиденциальности отсутствуют. То же самое относится к любой важной бизнес-информации.
Оптимальным решением для заказчика мы считаем обучение индивидуальной LLM. Такая модель может быть размещена внутри корпоративного контура, что решает вопросы, связанные с конфиденциальностью данных. Она будет работать с предоставленными данными, однако не сможет, например, написать научную работу с обзором мировых трендов, если подобные примеры не были изначально включены в набор данных для ее обучения.
Опубликовано 10.11.2024
